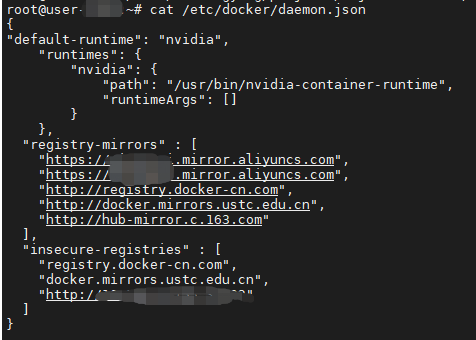
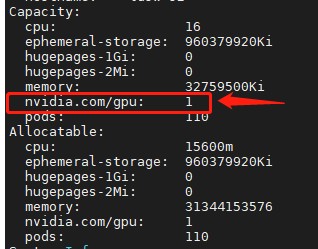
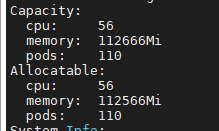
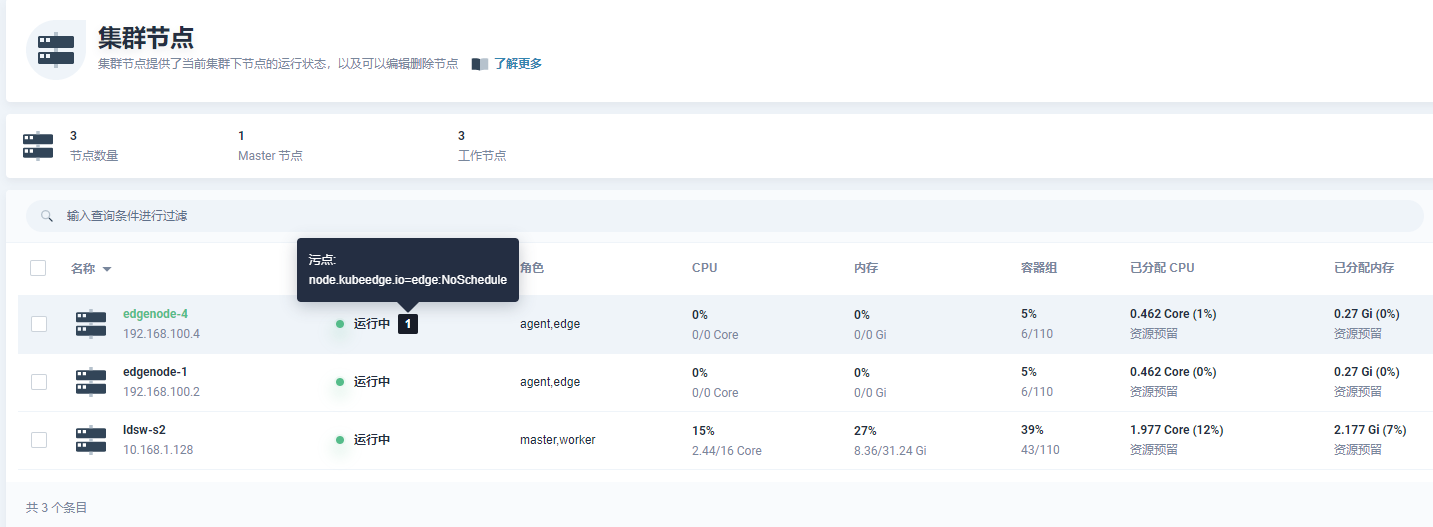
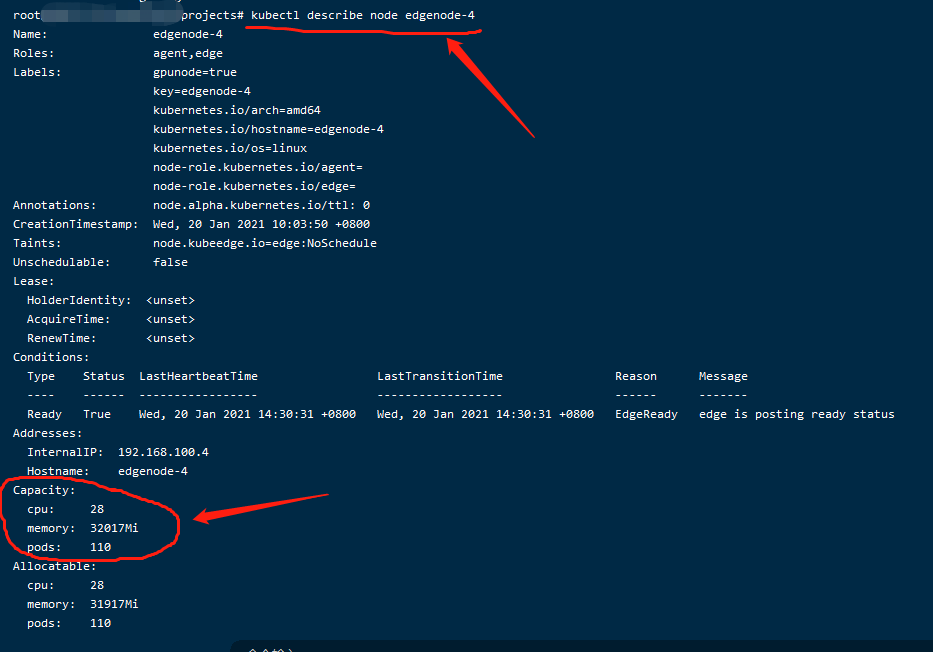
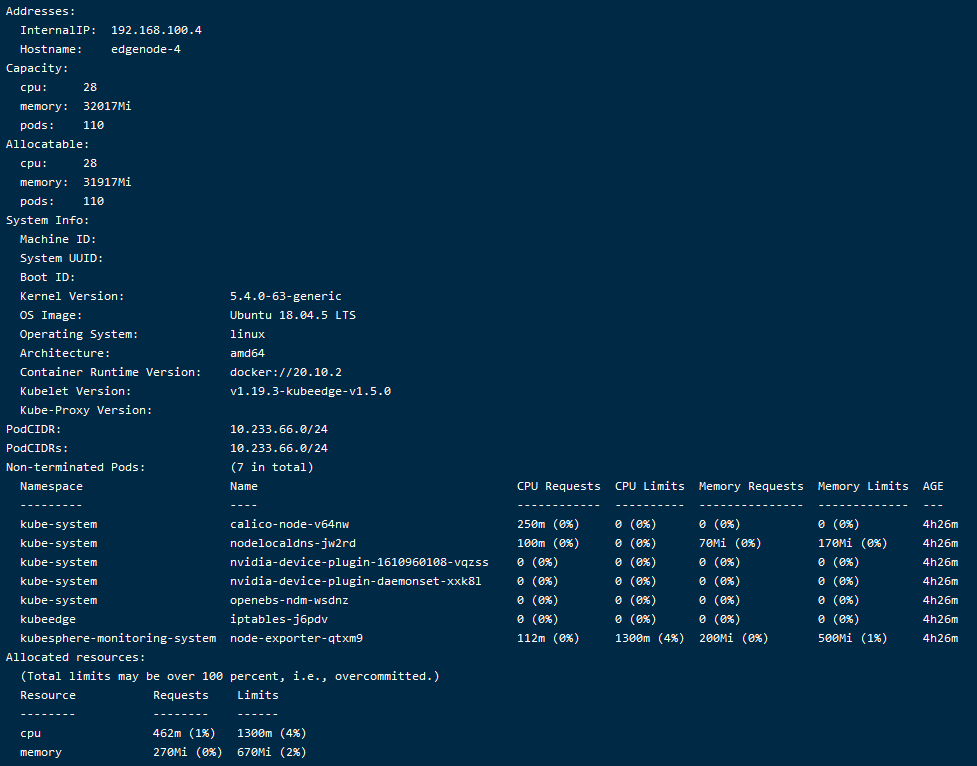
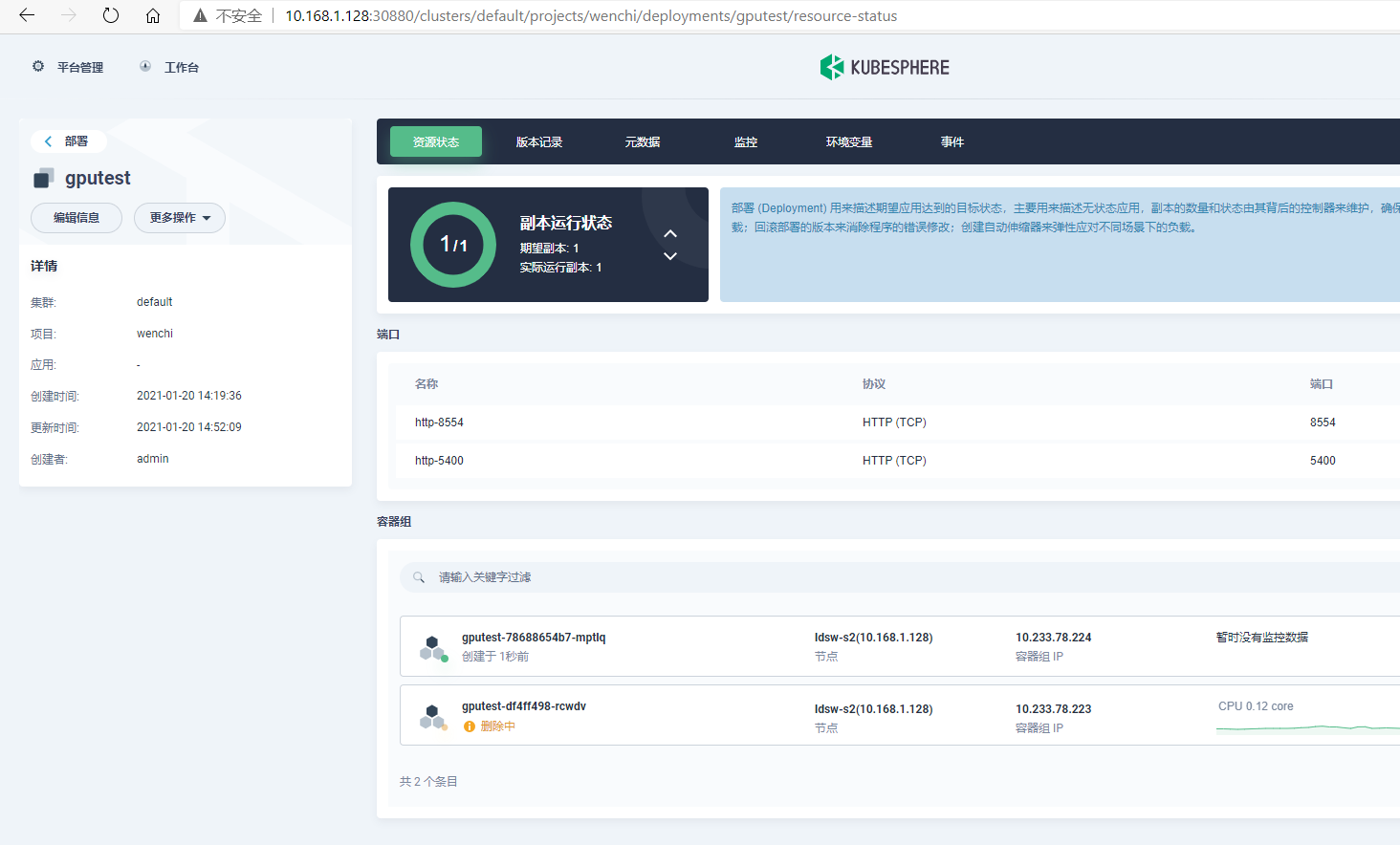
csuffyy 边缘节点情况: 操作系统信息:物理机 Ubuntu18.04,4C / 32G Kubernetes版本:v17.8,单节点 KubeSphere版本:v3.0.0,All In One 安装 **KubeEdge安装教程参考: 《KubeSphere 集成 KubeEdge 快速上手指南》 问题描述: 已根据https://github.com/NVIDIA/k8s-device-plugin 上的教程,安装好了nvidia-docker2、nvidia-device-plugin.yml等,修改了 /etc/docker/daemon.json 现在在master节点和work节点执行 docker run –rm –gpus all nvidia/cuda:10.2-base nvidia-smi 也都能正常运行,但是执行kubectl describe node <node>语句,master节点能看到Capacity的描述中包含nvidia.com/gpu: 1,work节点却没有,而且即使指定nodeSelector为work节点,workload也不能调度到指定的work节点。 master节点: work节点: 恳请各位大佬们帮忙提供一下排查思路,非常感谢!
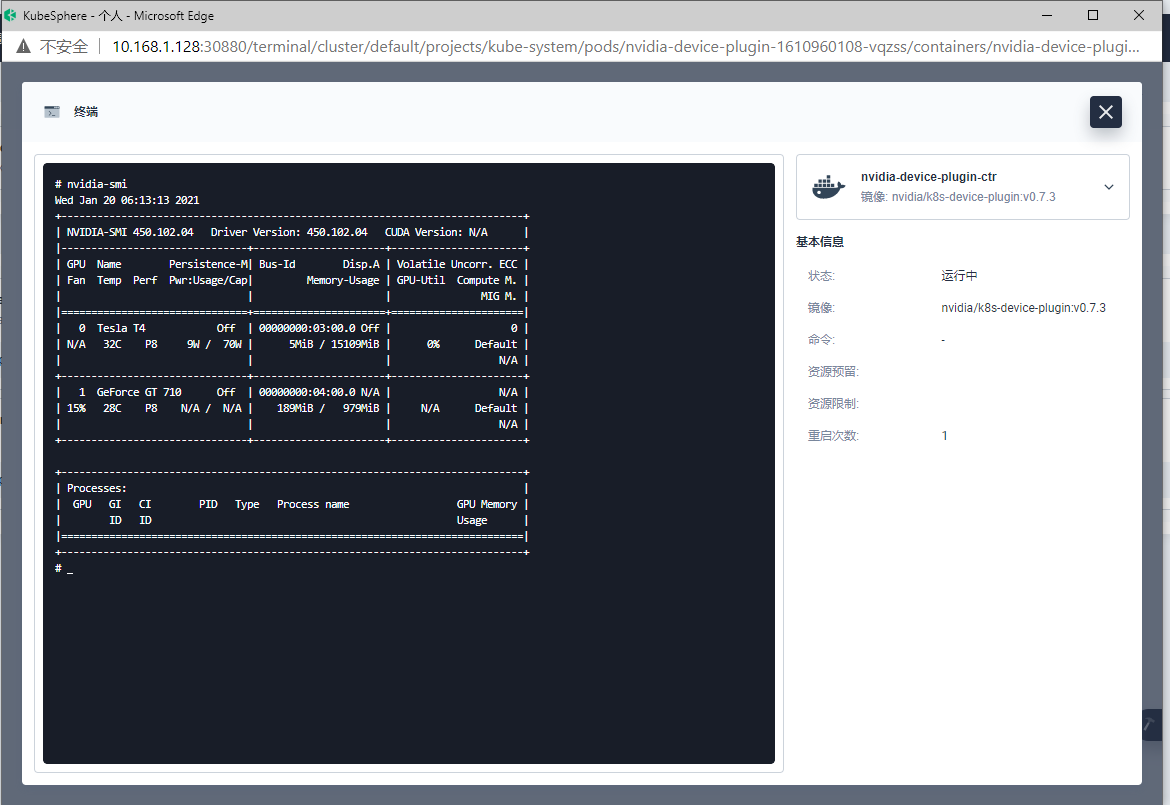
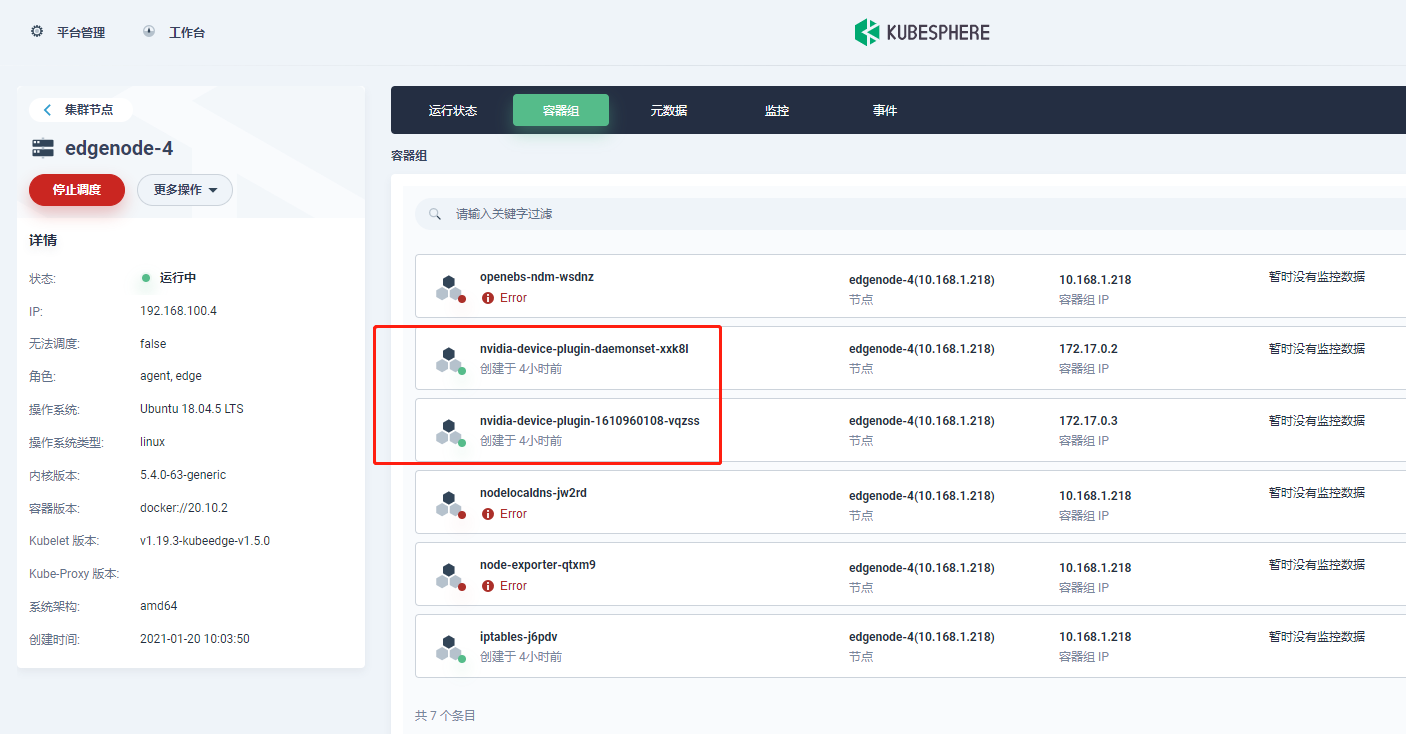
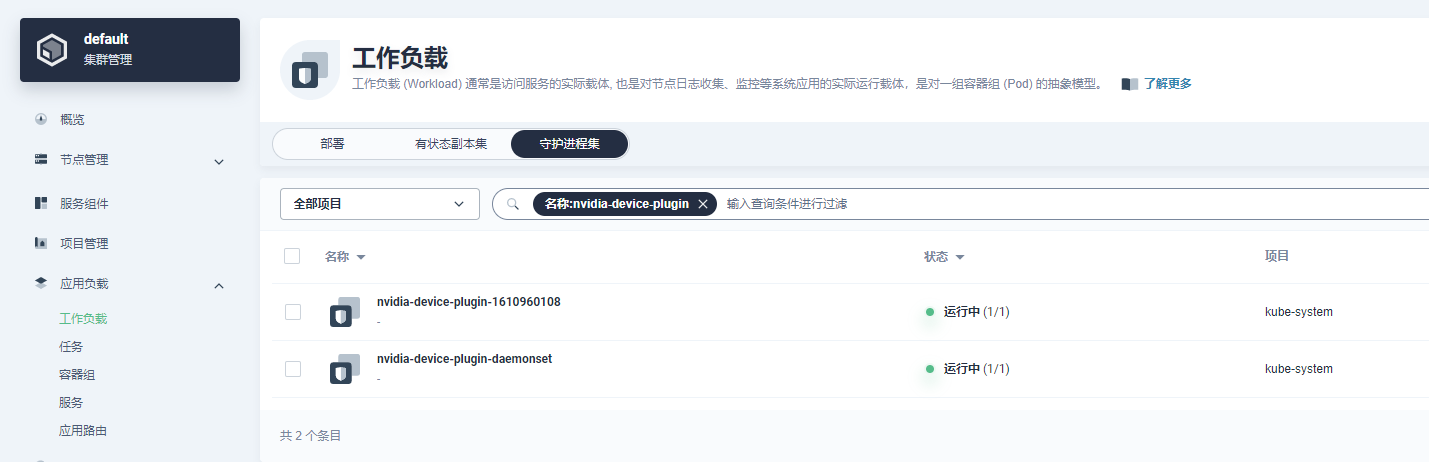
csuffyy Ma-Dan 两个节点一个有taint,一个没有taint,结果GPU工作负载都没调度过去,两个节点的信息里面Capacity中也都没有GPU信息。 边缘节点nvidia-device-plugin-daemon容器组中的日志如下: 在边缘节点的容器对话终端里输入nvidia-smi 命令,结果如下:
csuffyy 调度失败的GPU工作负载yml文件如下,其中所有节点都有 gpunode : true 的标签: apiVersion: apps/v1 metadata: name: gputest namespace: wenchi labels: app: gputest annotations: deployment.kubernetes.io/revision: '1' kubesphere.io/creator: admin spec: replicas: 1 selector: matchLabels: app: gputest template: metadata: creationTimestamp: null labels: app: gputest spec: volumes: - name: host-time hostPath: path: /etc/localtime type: '' containers: - name: gputest image: '10.168.1.155:30002/library/safety-helmet:2.2.1' ports: - name: http-8554 containerPort: 8554 protocol: TCP - name: http-5400 containerPort: 5400 protocol: TCP resources: limits: nvidia.com/gpu: '1' volumeMounts: - name: host-time readOnly: true mountPath: /etc/localtime terminationMessagePath: /dev/termination-log terminationMessagePolicy: File imagePullPolicy: IfNotPresent restartPolicy: Always terminationGracePeriodSeconds: 30 dnsPolicy: ClusterFirst nodeSelector: gpunode: 'true' serviceAccountName: default serviceAccount: default securityContext: {} imagePullSecrets: - name: harbor affinity: {} schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 25% maxSurge: 25% revisionHistoryLimit: 10 progressDeadlineSeconds: 600
Ma-Dan 有无taint都没有调度上,可能原因应该是nvidia-device-plugin,在节点以边缘节点方式加入时,无法像普通节点那样,把nvidia.com/gpu填充到capacity里面。
csuffyy Ma-Dan 如果在nodeSelector中明确指定调度到特定边缘节点,则显示 无法调度 : 调度失败的容器事件: 0/3 nodes are available: 1 node(s) had taints that the pod didn’t tolerate, 2 node(s) didn’t match node selector.` 是不是 tolerate 方面要做什么特别的设置呢?
Ma-Dan csuffyy 需要对边缘节点加taint,然后边缘节点工作负载加tolerate tolerations: - key: node.kubeedge.io operator: Equal value: edge effect: “NoSchedule”
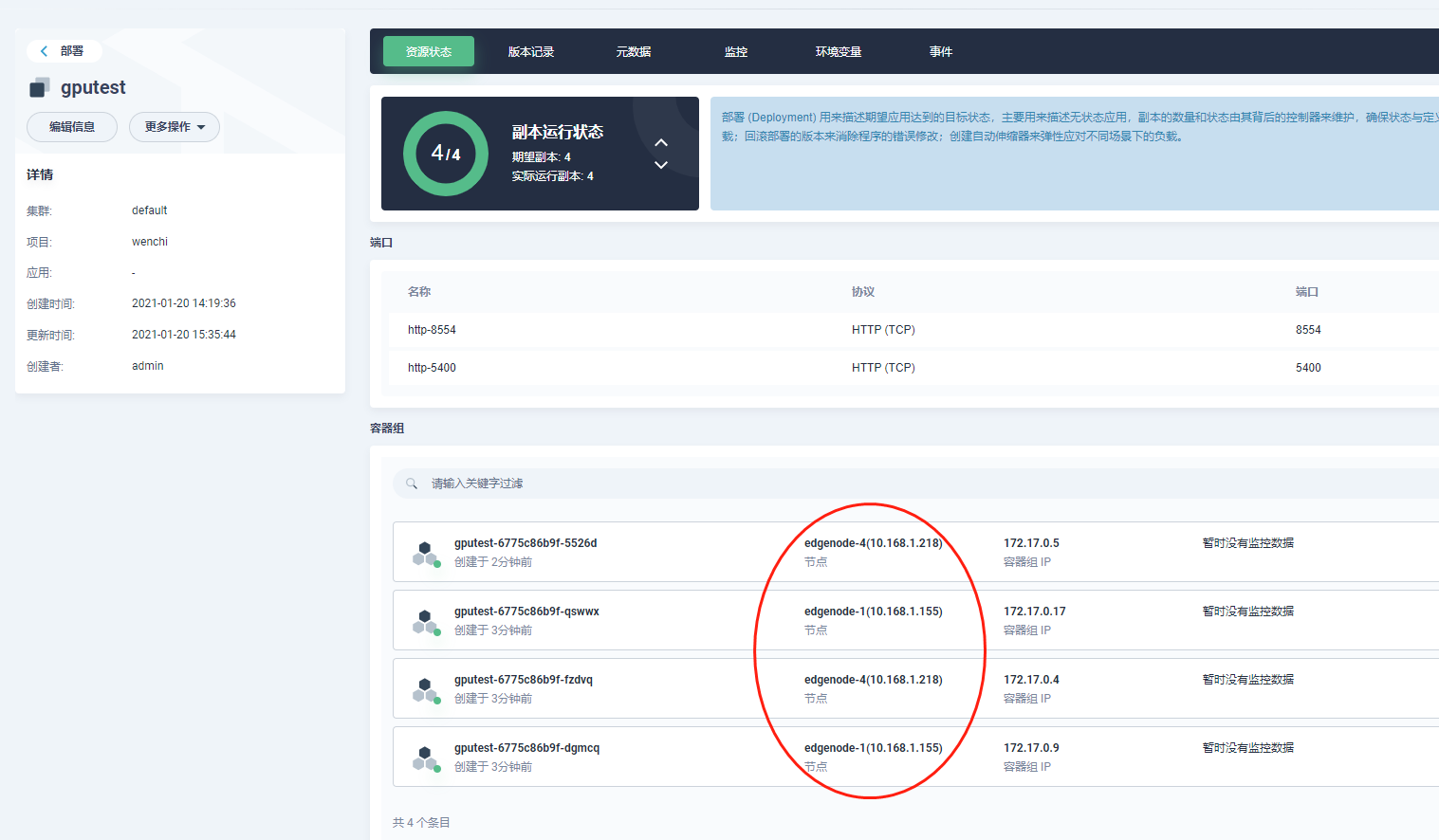
csuffyy Ma-Dan Ma-Dan 增加副本个数,看看能否调度到边缘节点上呢?或者再加一个只调度到边缘节点的标签。 😄 按照您的指导,操作以后发现,一开始增加副本个数,有污点的边缘节点是不能调度的,没有污点的边缘节点调度过去了。然后我把所有边缘节点的污点都删除了,现在已经可以成功调度到全部的两个边缘节点了,非常感谢您的热心指导!
Ma-Dan 自动生成的容器组里面,有些组件是不应该调度到边缘节点的,需要对这些组件(主要是daemonset)做如下调整: (1) calico-node 去掉 operator: Exists effect: NoSchedule 或者增加nodeselector,按照实际集群的云端节点label nodeSelector: node-role.kubernetes.io/master: "" node-role.kubernetes.io/worker: "" (2) nodelocaldns 去掉 operator: Exists effect: NoSchedule 或者增加nodeselector,按照实际集群的云端节点label nodeSelector: node-role.kubernetes.io/master: "" node-role.kubernetes.io/worker: "" (3) node-exporter 去掉 operator: Exists 或者增加nodeselector,按照实际集群的云端节点label nodeSelector: node-role.kubernetes.io/master: "" node-role.kubernetes.io/worker: "" (4) fluent-bit 修改 kubectl edit fluentbits -n kubesphere-logging-system fluent-bit 增加 nodeSelector: node-role.kubernetes.io/master: "" node-role.kubernetes.io/worker: ""
Ma-Dan csuffyy 目前看来边缘节点上nvidia-device-plugin似乎起不到作用,没有更新到capacity里面的GPU,那么暂时不调度过去也可以,让它在普通的GPU节点上上报GPU能力。